





Data privacy – could traditional approaches work for machine learning models?

Co-author
Jonathan Cohen
In the second of our two-part series on privacy in the age of big data, we explore the potential to apply data privacy approaches used in traditional settings to machine learning models. We also look closely at emerging approaches such as ‘machine unlearning’, and why the search for commercially robust solutions to help organisations comply with privacy requirements is no simple task.
Our lives are increasingly tied to artificial intelligence and machine learning, yet the consequences seem unclear – especially for our privacy – as countries scramble to navigate and keep pace with a world dominated by algorithms.
What does this mean for our privacy in Australia? In Part 1 of our series, we looked at changes to the Privacy Act 1988 under consideration by the Australian Government, and how these might impact machine learning models, the industries who use them and the consumers they target. While the review is still underway, we identified some practical steps organisations can take now to assess and reduce potential privacy implications of the proposed changes for their machine learning models and pipelines. This leads us to ask, could current approaches to protect people’s data in traditional data contexts – for instance, when sensitive information needs to be masked in government or company data – also be applied to machine learning models as we adapt to this changing privacy landscape?

Finding ways to keep private data hidden that work for business is increasingly challenging
In considering the question, we explore:
- The challenges in applying data privacy approaches in traditional data contexts
- A traditional data privacy approach and its applicability for machine learning – Differential privacy is a system that allows data about groups to be shared without divulging information about individuals. We look at whether its principles can be applied to machine learning models to prevent privacy attacks that allow probabilistic private information about individuals to be inferred, or deduced, with an accuracy significantly greater than a random guess.
- Emerging approaches – We investigate whether ‘unlearning’ techniques can be used to reduce the costs and time associated with retraining models in response to requests to delete personal information by customers under the ‘right to erasure’, one of the proposed changes to the privacy act.
1. Challenges of applying data privacy in everyday settings
At this stage, the application of data privacy approaches to machine learning models is still a maturing research area. Even in traditional data contexts, masking private information can be difficult, and unexpected privacy issues can still arise even after using standard de-identification techniques that are well developed and commonly implemented.
For example, the Australian Federal Department of Health unintentionally breached privacy laws when it published de-identified health data records of 2.5 million people online in 2016. Despite the published dataset complying with protocols around anonymisation and de-identification, it was found that the data entries for certain individuals with rare conditions could easily be re-identified by cross-referencing the dataset with a few simple facts from other sources such as Wikipedia and Facebook.
Re-identifying de-identified data – it’s a worldwide risk
Re-identification risks following the public release of granular datasets are not unique to Australia, with several recent cases emerging around the world. One such case relates to the National Practitioner Data Bank (NPDB), which is the national database for medical malpractice reports and disciplinary action in the United States. Although the names of individual doctors were removed in the publicly available de-identified dataset, several journalism organisations published investigative reports in 2011 that proved it was possible to match de-identified NPDB data entries to a specific doctor by cross-referencing other publicly available information. In response, the United States Department of Health and Human Services was forced to introduce a strict data use agreement stipulating that users must only use the data for statistical analysis, and specifically not to identify doctors and medical providers.
Search for solutions
These two examples demonstrate that even with the correct application of de-identification techniques, challenges commonly arise from the collation of released datasets with other publicly available information. This is a particular issue for granular datasets and individuals with unusual circumstances, often referred to as outliers.
It’s not all bad news, however, and several techniques are emerging to address these data privacy risks, as the quest to find solutions gains momentum. We explore some of these below and whether they might be applicable in machine learning environments.

Publicly sharing aggregate statistics gives a bird's eye view without revealing an individual's data
2. Differential privacy – a modern approach for traditional data contexts
In addition to releasing granular datasets, it is also common for companies and governments to share aggregate statistics and other high-level information about individuals within their datasets. Under normal circumstances, it can even be possible for information about specific individuals to be ascertained from these aggregate statistics, provided there is sufficient background information available on individuals within the population.
How to share without getting personal
Developed by researchers at Microsoft in 2006, differential privacy is a system that permits the public sharing of aggregate statistics and information about cohorts within datasets, without disclosing private information about specific individuals. It ensures that knowledge of the individual cannot be ascertained with confidence, regardless of what other information is known.
In practice, differential privacy is implemented by adding noise or randomness to a dataset in a controlled manner such that aggregate statistics are preserved. This approach means it is still possible to learn something about the overall population, but it is much more difficult (if it is feasible at all) to breach privacy as attackers cannot confidently extract exact values of private information data for individuals.
Fit for outwitting attackers
To illustrate, we consider a simple example of a dataset that contains information on whether individuals prefer to exercise during the day or at night.
Instead of publishing information on the specific individuals exercising at each time, statistics such as the mean or variance may be computed and shared based on the aggregate data to help protect individuals’ privacy. For instance, the published results might reveal that 70 out of 100 individuals prefer to exercise during the day, but not which exact people.
However, without differential privacy implemented, it may still be possible for a malicious attacker to use these aggregate statistics, along with information on a sufficient number of individuals’ exercise preferences, to infer private information for the remaining individuals within the dataset.
Make some noise with the flip of a coin
Differential privacy techniques can be implemented to address these risks. In its simplest application, random noise can be added through the flipping of a coin for each entry of the Exercises day or night? column (or field) in the data, as we illustrate in the diagram below. If the flipped coin shows heads, then no adjustment is made and the true entry of the Exercises day or night? column is returned. On the other hand, if the flipped coin shows tails, the coin is flipped again and the entry adjusted to be day (heads) or night (tails). These arbitrary small substitutions protect individuals’ privacy as it means that potential attackers can never know with certainty whether the output is randomly generated or the truth.
After the introduction of random noise, the statistics may reveal that the number of people who prefer to exercise during the day is 68 or 73, rather than the exact number of 70. This inaccuracy helps to preserve the privacy of individuals but has very little impact on the patterns of groups within the dataset – around 70 per cent of people still prefer to exercise during the day.
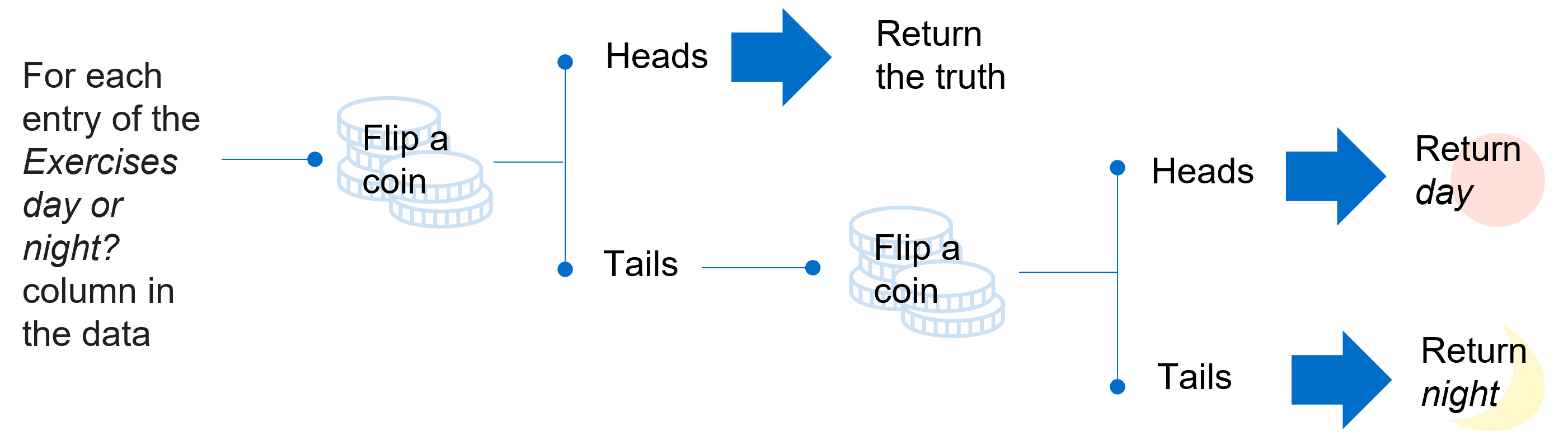
Introducing inaccuracy could thwart an attacker but preserve patterns and protect people's privacy
Well-deserved reputation for keeping people’s data safe
Differential privacy makes it possible for companies and governments to collect and share aggregate information about individuals’ behaviour, while maintaining the privacy of individual users. It has earned a well-deserved reputation providing principled and powerful mechanisms for ensuring privacy, and is an increasingly common approach in data governance settings. For example, Facebook has used differential privacy to protect data made publicly available to researchers analysing the effect of sharing misinformation on elections, while Uber has used it to detect statistical trends in its user base without exposing personal information.
Applying differential privacy to machine learning models
In broad terms, the introduction of noise under differential privacy conflicts with the philosophy of machine learning models, which typically rely on individual variation. Nevertheless, researchers have developed tools to apply differential privacy in machine learning, with the goal of limiting the impact of individual records used in the training dataset (data that helps to ‘train’ an algorithm or machine learning model) – particularly sensitive features – on model outputs. In turn, this limits the information about individuals that can be inferred from the model and its outputs.
Differential privacy can be implemented in machine learning algorithms in different ways depending on whether the task is supervised or unsupervised learning (under unsupervised learning, models work on their own, typically with unlabelled data, to discover patterns and information that were previously undetected). Common places where noise can be introduced into machine learning models include the training dataset, the predicted model outputs and gradients (in simple terms, the speed at which a machine learning model ‘learns’).

Adding 'noise' or randomness to a dataset puts a barrier between attackers and private information
Model performance vs privacy protection – a precarious balance
However, studies to date have found that while current mechanisms to apply differential privacy to machine learning models can reduce the risk of privacy attacks, they come at the cost of model utility and rarely offer an acceptable balance between the two. This means differential privacy settings that add more noise in order to provide strong privacy protections typically result in useless models, whereas settings that reduce the amount of noise added in order to improve model utility increase the risks of privacy leakage.
The cost to model utility is also reflected in the Warfarin study we discussed in Part 1 of our series, which considered a regression model that predicted the dosage of Warfarin using patient demographic information, medical history and genetic markers. Researchers also showed that the use of differential privacy techniques to protect genomic privacy substantially interfered with the main purpose of this model, increasing the risk of negative patient outcomes such as strokes, bleeding events and mortality beyond acceptable levels.
The hard truth about preventing privacy attacks
Despite differential privacy’s reputation, it cannot yet be implemented for challenging tasks such as machine learning models without substantial privacy compromises being made to preserve utility. Researchers concluded that alternative means of protecting individual privacy must be used instead in settings where utility and privacy cannot be balanced, especially where certain levels of utility performance must be met.

Achieving effective model performance and privacy protection is an evolving balancing act
3. ‘Unlearning’ techniques
Also in Part 1, we explored the implications of the ‘right to erasure’ for machine learning models, and found that in addition to the deletion of the individual’s data itself, any influence of the individual’s data on models may also be required to be removed upon customer request.
Striving for efficiency
The most straightforward approach to achieve this is to retrain machine learning models from scratch using an amended dataset excluding the individual’s data, but this is often computationally costly and inefficient, particularly for large datasets and frequent erasure requests.
Alternative ‘unlearning’ techniques have been developed with the aim of avoiding these inefficiencies. These techniques are applied to ensure that a model no longer uses the data record that has been selected for erasure – in other words, they guarantee that training a model on a person’s data record and unlearning it afterwards will produce the same model distribution as if it were never trained on the data record at all. But ‘forgetting’ data is not an easy path for a model.
Why is unlearning so challenging for machine learning models?
Applying and implementing unlearning techniques for machine learning models is not straightforward for the following reasons:
- Limited understanding of how each data record impacts the model and its parameters – Little research has been conducted to date to measure the influence of a particular training record on parameters for most machine learning models, with the few techniques tested so far found to be computationally expensive for all but the simplest of machine learning models.
- Randomness in training methods and learning algorithms – A great deal of randomness exists in the training methods for most complex machine learning models, for example small batches of data are randomly sampled from the training dataset during model training. By design, learning algorithms are applied to search a vast hypothesis space (the set of candidate models from which the algorithm determines the best approximate for the target function).
- Incremental training procedures – For most machine learning, the development process is incremental, meaning that an initial model is developed and then incrementally improved or updated as new data becomes available. As such, it is complex to remove the impact of training a model on an individual training record at a particular stage, as all subsequent model updates will depend on that training point, in some implicit way.
Break it down – honing in on ‘slices’ and ‘shards’ of data
One emerging unlearning technique that has been designed to overcome these challenges is Sharded, Isolated, Sliced and Aggregated (SISA) training, a framework that speeds up the unlearning process by strategically limiting the influence of an individual data record during training.
Under SISA training, the training data is divided into multiple shards or pieces so that a single shard becomes a separate data record. By training models in isolation across each of these shards, only the affected models will need to be retrained when requests to erase an individual’s data are made, limiting retraining costs as each shard is smaller than the entire training dataset.
In addition, each shard’s data can be further divided into slices and presented incrementally during training, rather than training each model on the entire shard directly. Slicing further decreases the time taken to unlearn, albeit at the expense of additional storage, as model retraining can be started from the last known point that does not include the data record to be unlearned (identified from records of the model parameters that are saved before introducing each new slice).

SISA training divides data into smaller shards to assist models in unlearning a person's information
DaRE to dream – random forests spread their roots
Another emerging technique that supports adding and removing training data with minimal retraining is data removal-enabled (DaRE) forests, a variant of random forests, which are a popular and widely used machine learning model that consists of an ensemble of decision tree models (another type of machine learning model that successively splits the data into different segments along ‘branches’ and ‘leaves’).
DaRE makes retraining more efficient through two techniques:
- Reducing dependency of the model structure on the dataset
- Only retraining portions of the model where the structure must change to match the updated dataset.
DaRE randomises both the variables used and the thresholds adopted for splitting in the upper layers of trees so that the choice is completely independent of the dataset and so this part of the model never needs to be changed or retrained. As splits near the top of each tree contain more data records than splits near the bottom and are therefore more expensive to retrain, strategically placing random splits near the top of the tree avoids retraining the parts that are most costly.
This randomised structure also helps to reduce the retraining required, as individual data records are isolated to certain parts of the tree (‘subtrees’). When adding or removing data, stored data statistics for each level of the subtree are updated and used to check if a particular subtree needs retraining, which limits the number of computations through the data.
But are these techniques any good?
Studies using real-world datasets have shown that both of these techniques are materially faster than retraining models from scratch, while sacrificing very little in predictive model performance. For instance, researchers found that, on average, DaRE models were up to twice as fast as retraining from scratch with no loss in model accuracy, and two to three times faster if slightly worse predictive performance was tolerated.
However, techniques do not always provide the expected benefits. Testing revealed that these speed-up gains from SISA training exist only when the number of erasure requests is less than three times the number of shards. Care must be taken when increasing the number of shards, as using a smaller amount of data to fit each model may make them less accurate, particularly for complex learning tasks.
The fine print
Other drawbacks of these emerging techniques are the large storage costs associated with them and their limited applicability across all machine learning algorithms. For instance, SISA training works best when models learn by iterating through the data (such as via stochastic gradient descent) and is not suitable for algorithms that must operate on the entire dataset at once.
There are also likely to be challenges in implementing them in practice, as these approaches cannot be retrofitted onto current systems and would require retraining of existing models and a fundamental redesign of existing machine learning pipelines with unclear effects.

DaRE reduces the need to retrain models to 'unlearn' data by splitting upper parts of decision trees
The future looks …?
The proposed changes to the privacy act may place significant governance and compliance burdens on organisations. Moreover, if tough positions are taken on items such as privacy of inferred data and right to erasure, then it may not even be feasible for organisations to comply with these requirements while continuing to operate complex and evolving machine learning systems.
Although the application of existing data privacy approaches and emerging unlearning techniques to machine learning have shown some promise, this area of research is still in the very early stages of development. We cannot be certain that further research will result in commercially robust solutions that allow organisations to avoid investing in onerous and expensive procedures to ensure compliance. As shown by the unacceptable utility-privacy compromise for differential privacy, there may also be some fundamental limitations on achieving compliance via shortcuts.
In future, it will be important to promote and invest in research for solutions that maintain privacy, while also providing other desirable model properties such as transparency and explainability. In the interim, if the proposed amendments to the privacy act are enacted and interpreted as applying to machine learning models, organisations may be forced to significantly simplify their modelling approaches and infrastructures to have a better chance of meeting compliance obligations.
Related articles
Related articles
More articles

How AI is transforming insurance
We break down where AI is making a difference in insurance, all the biggest developments we’re seeing and what's next for insurers
Read Article
How AI will be impacted by the biggest overhaul of Australia’s privacy laws in decades
Understand the key changes to the Privacy Act 1988 that may impact AI and how organisations who use AI can prepare for these changes.
Read Article